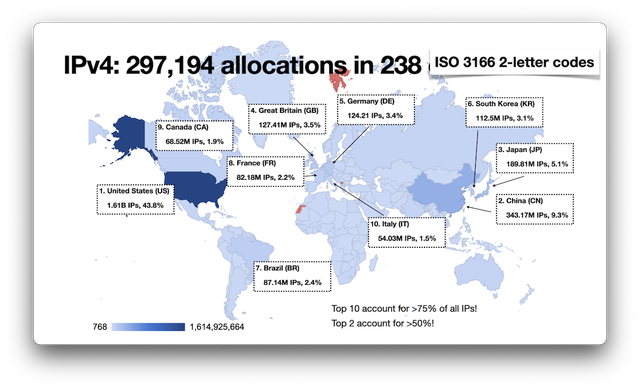
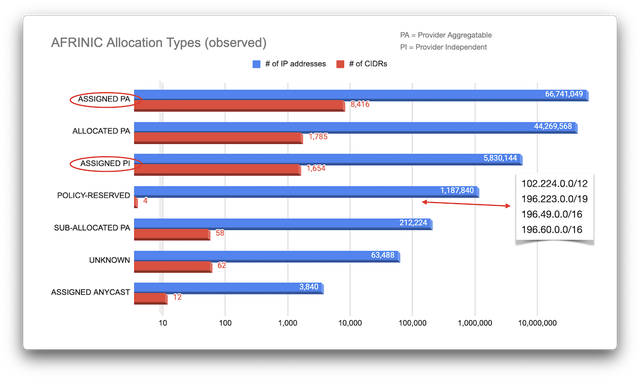
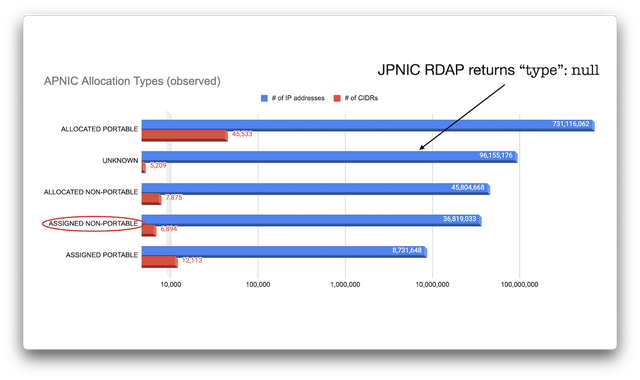
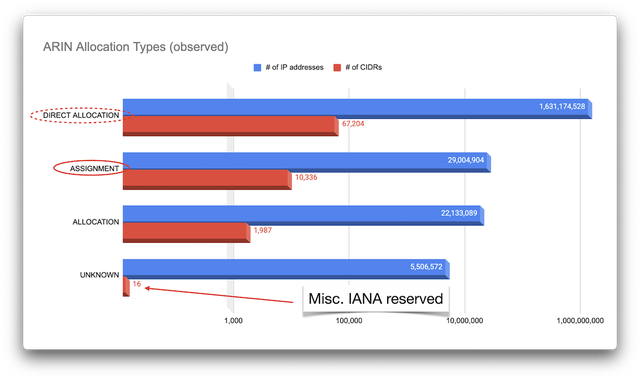
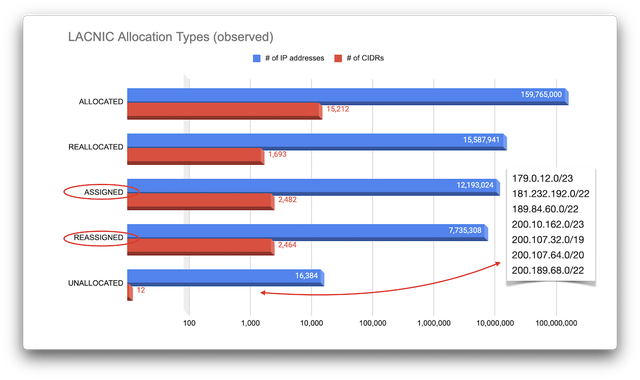
> **本文基于一次长程AI调查式对话的整理重现,侧重结构性事实与企业/人物之间的利益链路,而非媒体叙事。**
—
一次普通机房搬迁,了解 IDC 圈尘封十五年旧账
近期不少 RackNerd 用户收到洛杉矶 DC2 机房节点迁移的官方工单,在普通散户眼里,这只是一次常规的硬件升级、网络优化,无非是短暂的线路抖动、额外的数据备份工作,过后便恢复如常。但对于深耕海外低价 VPS 行业五年以上的圈内从业者、老站长而言,这次迁移绝非一次简单的运维调整,它像一把钥匙,重新打开了洛杉矶 Multacom 大楼尘封多年的恩怨往事。
RackNerd 如今的业务版图遍布全球 21 个数据中心,但洛杉矶 DC2 节点的底层根基,始终绑定在洛杉矶圣塔克拉拉 6171 Century Blvd 的 Multacom 大楼体系内。这栋老式商用机房大楼,曾是老牌机房运营商 QuadraNet 的核心大本营,承载了它最鼎盛时期的机柜资源、带宽链路与 IP 网段;而如今,大楼业主 6171 Century LLC 与 QuadraNet 深陷租金诉讼,起诉对方拖欠租金高达 37.6 万美元,甚至采取封锁机房门禁、限制设备物理访问的强硬手段。

这场当下正在发酵的租赁纠纷,从来不是偶然的商业矛盾,而是 2019 年那场轰动整个海外主机圈无预警拔线事件的后续余波。QuadraNet 的衰落、廉价 VPS 市场格局重构、RackNerd 的崛起,全部因果闭环,都藏在这栋大楼里,也藏在创始人 Dustin B. Cisneros 的双面人生与资本套利布局之中。
本文基于公开法院案卷、加州州务卿工商档案、PACER 联邦法院检索记录、行业论坛历史存档交叉核验,以叙事化笔触还原整件事全貌,同时嵌入标准化事件时间线、核心关系数据表、业务链路结构图,兼顾故事可读性与调查严谨性,全程区分可核验事实、合理强推论、社区网传传闻,不主观臆造、不情绪化渲染。
一、双面创始人 Dustin:光鲜履历与地下操盘的割裂人生
如今的 Dustin B. Cisneros,是妥妥的行业新锐企业家。翻开 RackNerd 官方宣传、Inc.5000 权威榜单、HostAdvice 专业采访,他的履历完美贴合硅谷创业者的标准模板:2008 年入局互联网主机行业,早年创办 SemoWeb LLC 深耕廉价虚拟主机赛道;2013 年入职老牌机房 QuadraNet,一路晋升至销售经理核心岗位;2019 年创立 RackNerd LLC,公司注册于加州兰乔库卡蒙格;2024 年登顶 Inc.5000 全美榜单第 1506 位,三年营收增长率高达 342%,2025 年入选太平洋区域 Inc. 百强企业。对外公开话术里,他始终以「行业资深老兵、以客户体验为核心」自居,绝口不提自己早年操盘的一众廉价 VPS 品牌。
但在 LowEndTalk、WebHostingTalk 两大海外主机社区的历史存档里,藏着 Dustin 不为人知的另一面。任职 QuadraNet 销售经理的六年间,他手握机房批发定价权、新分销商审批权、资源调配权,背地里隐秘操盘AlphaRacks、NFP Hosting、Woothosting、HostMyBytes四大廉价 VPS 品牌,形成庞大的地下运营矩阵。

这份双重身份之所以能长期隐匿不被发现,核心依托两点:一是 QuadraNet 粗放的内部管理漏洞,销售高管拥有极大的自主审批权限,缺乏审计与风控制衡;二是美国加州 LLC 有限责任公司的注册隐私规则,无需公开实际控制人信息,完美为他搭建了隐身屏障。也正是这层身份与权限,让 Dustin 找到了可以长期套利的商业漏洞,改写了整个北美廉价 IDC 行业的格局。
二、QuadraNet 底层商业模式:天生存在漏洞的套利温床
想要读懂 Dustin 的全套操作逻辑,首先要拆解 QuadraNet 当年的核心生意模型。作为洛杉矶头部机房批发商,QuadraNet 手握 Multacom 大楼大量长租机柜,批量采购 Cogent、Telia、GTT 等顶级骨干运营商的大宗带宽,搭建起完整的底层基础设施,业务分为两大核心板块:直接面向大企业的定制化独立服务器、机房托管直销业务,以及面向中小商家的机柜、IP、带宽批发业务。
在批发合作模式下,QuadraNet 只和分销商结算三项固定费用:机柜 / U 位的机位租金、ARIN 官方分配的 IP 地址段月租、以及行业通用的95th percentile(第 95 百分位)带宽费用。其中机位和 IP 定价透明、成本固定,几乎没有套利空间,而 95 百分位带宽计费规则,成为了 Dustin 实现低成本暴利的核心工具。
95th 百分位计费:廉价 VPS 行业的利润杠杆
很多人听过这个计费名词,却不懂底层逻辑。QuadraNet 每 5 分钟采集一次合作分销商的带宽速率,一个月累计近万组采样数据,系统会将所有速率从低到高排序,直接剔除月度最高 5% 的突发流量峰值,以剩余流量的最高点作为最终计费标准。
对于普通 VPS 商家而言,带宽占整体运营成本的 40%-55%,是最大开支项。Dustin 精准拿捏了这个规则的漏洞:绝大多数廉价 VPS 用户日常仅用于搭建小站、轻度代理、数据探针,95% 的时间带宽占用极低,只有偶尔备份、测速时出现短时流量尖峰。数千个散户用户叠加后,整体带宽数据呈现「大批量低值 + 零星高峰」的特征,95 百分位规则会自动抹掉所有尖峰,最终给到 QuadraNet 的计费带宽始终维持在极低水平。
而 Dustin 的操作手法简单且精准:利用 QuadraNet 销售经理的权限,给自己控制的壳公司审批远低于市场的内部专属批发价,在廉价带宽链路上上架海量月租 1-3 美元的超低价 VPS;后端向 QuadraNet 支付极低的带宽账单,前端向用户收取全额年付预收款,赚取中间巨额价差。这并非物理层面的资源偷窃,而是利用职务特权、行业规则漏洞完成的合规套利。
更关键的是,正常入驻 QuadraNet 的分销商,必须经过企业资质审核、押金缴纳、信用背调、付款能力核验全流程,但 Dustin 凭借审批权限,直接为自己的壳公司绕过所有风控门槛,无需押金、无需资质核验,凭空拿到优质资源配额,这也成为 QuadraNet 后续内控崩盘的核心隐患。
三、隐秘壳矩阵:稻草人挂名 + 影子合伙人,完美风险隔离
为了彻底切割自己与四大 VPS 品牌的关联,规避 QuadraNet 内部风控与后续法律追责,Dustin 搭建了一套成熟的壳公司运营体系,利用美国 LLC 隐私漏洞、挂名服务规则,把真实受益人彻底隐藏在幕后。
稻草人 Julian Jin:纸面切割的关键棋子
AlphaRacks 作为整个矩阵的核心主体,在加州州务卿工商登记中,登记的法定代表人并非 Dustin,而是一个名叫 Julian Jin 的陌生人。受加州法律限制,LLC 公司无需公开股东与实际控制人,仅对外展示注册代理公司地址,这就给了挂名操作可乘之机。
结合行业规则与商业逻辑可强推论:Julian Jin 并非品牌真实创始人,只是典型的Straw Man(稻草人挂名者),要么是 Dustin 的熟人借名,要么是美国市面上售价 99 美元标准化挂名服务的第三方人员,唯一作用就是在工商纸面上,切断「QuadraNet 员工 = AlphaRacks 实控人」的关联链路。
最有力的破绽出现在 2019 年 5 月 AlphaRacks 倒闭官方声明中,这份发布在 Twitter 且被网页存档留存的公告,刻意强调「AlphaRacks 由 Julian Jin 全资持有,与 QuadraNet 前员工无任何关联」,但留给数万受灾用户的售后联系方式,赫然是 QuadraNet 官方销售邮箱 sales@quadranet.com。
从商业逻辑来看,一家宣称完全独立、自有服务器的第三方公司,绝不可能让用户去找上游机房官方对接售后。唯一合理的解释:这份声明是 QuadraNet 法务部主导的危机公关文案,目的是对外切割责任,把员工套利事件包装成第三方商家自主经营倒闭,规避品牌舆论风险。
多品牌合并:虚增规模,摊薄运营成本
Dustin 对外宣称 AlphaRacks 先后收购 NFP Hosting、Woothosting、HostMyBytes 三大品牌,将所有用户统一迁移至同一网段与 WHCS 管理后台。这并非单纯的业务扩张,而是精准的规模套利手段:一方面合并服务器与带宽采购量,向 QuadraNet 申请更低的批发单价,进一步压缩成本;另一方面对外宣称坐拥 2.3 万 + 用户,在 LowEndBox 等广告平台提升投放可信度,吸引更多用户年付充值,用新用户的现金流覆盖上游机房账单。
整套模式本质是现金流滚雪球玩法,只要新用户持续入局,就能维持运营周转,完全没有应对突发风险的备用方案,也为后续瞬间崩盘埋下伏笔。
影子合伙人 Adam NG:全程隐身的幕后参与者
在 QuadraNet 内部风控通告中,除了 Dustin,还明确点名另一位核心参与者 Adam NG。但这位人物至今没有任何公开可核验的档案:无公开领英资料、无加州 / 内华达州工商注册记录、无司法涉案案卷留存,2019 年与 Dustin 同步被开除后,彻底从行业公开视野中消失。
行业 LowEndTalk 等论坛流传着一条未经证实的传闻:Adam NG 后续化名入职 SpinServers 继续从事低价 VPS 分销业务。但经过多轮公开档案检索,没有任何法院文书、工商记录能佐证这一说法,因此仅作为社区流言留存,无法定性为事实。从整件事格局来看,Adam NG 是典型的影子操作者,手握机房后台权限参与分成,全程不出面、不公开,出事由 Dustin 与 Julian Jin 挡在前台。
四、2019 年拔线事件完整复盘:合法止损下的数万用户牺牲
标准化事件时间线
| 大致时间 | 核心关键事件 |
| 2019 年 5 月中旬 | QuadraNet 内部完成风控审计,查实 Dustin 利用职务权限、虚假资质为壳公司套取低价资源,认定存在利益冲突与合同欺诈 |
| 审计当日 | QuadraNet 直接执行端口封禁、物理拔线、IP 段路由封禁,AlphaRacks 全系品牌所有服务器全网离线,无任何前置通知 |
| 停机数日内 | 工单系统、服务器管理面板全面失联,用户无任何数据备份、迁移渠道 |
| 2019 年 5 月 17 日 | AlphaRacks 发布法务拟定倒闭声明,以 Julian Jin 名义切割关联,预留 QuadraNet 官方售后邮箱 |
| 同期 | Dustin B. Cisneros 与 Adam NG 被 QuadraNet 正式开除,劳动关系即刻终止 |

整个事件最具争议的点,在于 QuadraNet 自始至终没有给用户预留任何数据迁移窗口期。而从法律层面,QuadraNet 手握绝对主动权,依据双方签署的主服务协议(MSA),合同明确要求合作分销商必须提交真实经营资质、无利益冲突;若存在欺诈性签约、重大违约行为,机房有权无条件单方面终止服务、扣留设备,且无需为下游散户提供数据备份与迁移 SLA。
站在企业合同视角,QuadraNet 的操作完全合规;但站商业伦理与用户权益角度,数万无辜站长、开发者、小企业主沦为企业内控纠纷的牺牲品,付出了惨痛代价。事件最终的用户结局近乎无解:所有服务器设备被 QuadraNet 留置扣押,用户数据基本全部永久丢失;AlphaRacks 作为空壳 LLC 公司,账户无任何可执行资产,用户 PayPal 退款申诉大多因超时效、追责主体不符失败;用户与 AlphaRacks 签署的服务协议无法约束 QuadraNet,想要穿透公司壳层追责实控人,又缺乏司法案卷举证,追偿路径彻底断裂。
五、深度拆解:为何无刑事立案、无公开诉讼?
这是整件事外界最疑惑的核心问题:波及数万用户、存在明确员工套利与合同欺诈,最终却无人被罚款、无人被判刑,甚至没有一场公开诉讼。我们通过 PACER 联邦法院、CourtListener、洛杉矶县高等法院多维度关键词检索,得出明确结论:没有任何可公开核验的 QuadraNet 起诉 Dustin 的案卷,网传 2022 年双方诉讼、听证会等说法,均为论坛自媒体杜撰,无案号、无法律文书佐证,纯属谣言。
美国司法五大核心追责障碍
| 追责壁垒 | 详细解析 |
| 受害主体错位 | 刑法直接受害方为 QuadraNet 本身,散户属于间接受害者;且 QuadraNet 自身内控严重失职,存在连带过失,降低司法立案优先级 |
| 主观举证门槛极高 | 刑事欺诈必须证明「蓄意主观欺骗」,Dustin 仅需辩称属于销售灰色激励权限,即可形成合理怀疑,无法定罪 |
| 单案金额碎片化 | 单个用户损失仅 20-200 美元,集体总金额看似庞大,但检察官不会消耗司法资源处理小额集体纠纷 |
| LLC 法人面纱保护 | 债务与纠纷全部归属壳公司,若无资产混同实锤,无法追溯 Dustin 个人法律责任 |
| 检察自由裁量 | 检察机关以重大刑事案件定罪率为核心 KPI,散户互联网小额纠纷不属于优先办案范畴 |
从实际处置逻辑来看,QuadraNet 选择了最符合自身利益的方式:内部开除当事人、行使合同自助救济扣留设备、签署保密协议与互不追诉条款。之所以不愿公开起诉,核心顾虑在于庭审会触发证据开示,自身管理失控、内控漏洞会被彻底公开,重创企业商业口碑,得不偿失。
中美 IDC 行业监管与追责模式对比
| 对比维度 | 中国监管体系 | 美国本次处置结果 |
| 行业准入 | 强制增值电信牌照,无证直接关停追责,行业有准入门槛 | 仅 LLC 填表注册即可营业,无前置资质审核约束 |
| 集体受害处置 | 大规模用户受损易触发公安经侦主动介入,公权力强势干预 | 默认归属民事合同纠纷,公权力不主动介入民间商事矛盾 |
| 事件后果公示 | 判决书全网公开,涉事人易纳入失信名单,行业受限 | 壳公司破产了事,责任人可换主体重新创业,无公开惩戒记录 |
这并非美国纵容商业欺诈,而是两国法律体系、监管逻辑的底层差异:中国将大规模民众财产受损纳入公共秩序管辖,公权力主动下场;美国优先遵循私法自治,把纠纷留给企业与个人自行解决,制度齿轮最终消解了追责的可能性。
六、QuadraNet 的自我反噬:PacificRack 复刻悲剧走向衰败
拔掉 AlphaRacks 网线后,QuadraNet 看似止损,却犯下了致命的战略误判。当时 AlphaRacks 倒闭留下数万价格敏感型用户市场真空,QuadraNet 自恃有机房、IP、带宽底层资源,认为完全可以亲自下场承接业务,随即推出零售 VPS 品牌 PacificRack,主打 2-5 美元低价套餐,支持支付宝、PayPal 支付,精准投放 LowEndBox 低价社区,意图吃掉这块市场红利。
但 QuadraNet 始终没认清一个核心本质:机房批发商与 VPS 零售商是两套完全相反的运营逻辑。QuadraNet 的核心能力是机柜运维、骨干网络搭建、大客户批发对接,缺乏零售必备的精细工单售后、网络滥用应急处理、资源调度平衡、用户退款体系。
PacificRack 上线后迅速口碑崩盘,无故封号静默停机、私自篡改服务器配置、IP 无理由封禁成为常态,工单往往数周无人回复,仅在负面舆论发酵时才临时冒泡敷衍。更有业内技术观察推测,其 VLAN 网段设计存在严重运维漏洞,大量 IP 塞入同一广播域,极易引发网络拥堵,虽无公开实锤,但用户大面积卡顿已是不争事实。
讽刺的是,2024 年 3 月 PacificRack 正式发布关停公告,要求用户限期自行备份数据,逾期强制停机,官方不提供任何数据协助与退款服务。五年前 QuadraNet 对 AlphaRacks 用户做的无预警停机、弃用户数据于不顾,五年后完整复刻在自己的零售品牌身上,形成极具宿命感的闭环。
而这只是 QuadraNet 衰落的开始。深陷 Multacom 大楼 37.6 万美元欠租诉讼、现金流持续断裂后,2025 年 QuadraNet 被迫出售旗下 20 万 + IPv4 核心地址段给 HostPapa——IPv4 是 IDC 行业最核心的硬通货,变卖核心资产等同于饮鸩止渴。2024 年 4 月,澳洲边缘数据中心运营商 Edge Centres 完成对 QuadraNet 的全资收购,其全美 10 城节点、AS 网络链路被逐步整合,曾经的洛杉矶老牌机房巨头,彻底沦为被收购的历史遗留资产,失去独立运营能力。
七、Dustin 洗白重生:RackNerd 的合规化转型与现状
2019 年风波沉寂数月后,Dustin 以全新实体 RackNerd LLC 重新入局,彻底抛弃了早年依托 QuadraNet 员工特权的灰色套利模式,完成商业模式的全面洗白与升级。
如今的 RackNerd 彻底摆脱单一机房依赖,不再依靠内部权限套取低价资源,转而与 ColoCrossing、Sharktech、MC 等多家主流机房签订正规公开批发合同。其中ColoCrossing 是 RackNerd 最核心的上游供应商,二者无任何股权关联、无共同母公司,是纯粹的房东与租户关系:ColoCrossing 拥有自建机房与骨干带宽,RackNerd 租用机柜、IP 与带宽,搭建 KVM 虚拟化平台二次零售,这也是海外 IDC 最标准的「机房批发商 – 品牌转售商」模式。
对比 Dustin 前后两种经营模式,风险结构发生根本性改变:AlphaRacks 时代完全依附单一机房员工权限,随时可能被无预警拔线,品牌无长期信誉赌注;如今 RackNerd 遵循正规商业合同解约流程,断网风险可预判,同时冲击 Inc.5000 权威榜单,绑定品牌口碑,经营风险大幅降低。
目前 RackNerd 已布局全球 21 个战略数据中心,依靠高额联盟营销、黑五常态化促销快速扩张,营收规模稳步增长。但历史遗留的信用成本始终无法抹去:行业论坛永久留存 2019 年拔线黑料,任何企业尽职调查都能追溯到创始人过往经历;同时品牌依旧高度依赖年付预收款现金流滚动,没有自有物理机房,底层命脉始终掌握在上游机房手中。对于普通用户而言,RackNerd 仅适合搭建可快速重建的无状态轻量业务,绝不建议存放唯一核心数据。
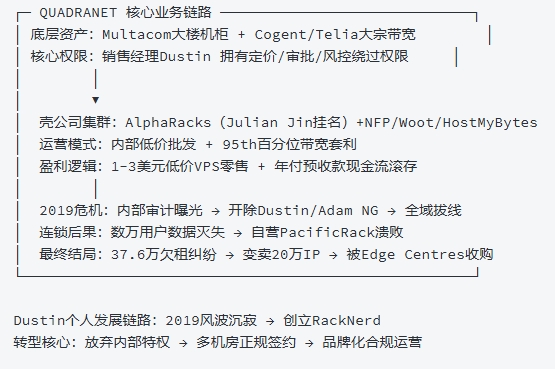
八、全业务链路拓扑结构图
┌─ QUADRANET 核心业务链路 ─────────────────────────────┐
│ 底层资产:Multacom大楼机柜 + Cogent/Telia大宗带宽 │
│ 核心权限:销售经理Dustin 拥有定价/审批/风控绕过权限 │
│ │
│ ▼
│ 壳公司集群:AlphaRacks(Julian Jin挂名)+NFP/Woot/HostMyBytes
│ 运营模式:内部低价批发 + 95th百分位带宽套利
│ 盈利逻辑:1-3美元低价VPS零售 + 年付预收款现金流滚存
│ │
│ 2019危机:内部审计曝光 → 开除Dustin/Adam NG → 全域拔线
│ 连锁后果:数万用户数据灭失 → 自营PacificRack溃败
│ 最终结局:37.6万欠租纠纷 → 变卖20万IP → 被Edge Centres收购
└────────────────────────────────────────────────────┘
Dustin个人发展链路:2019风波沉寂 → 创立RackNerd
转型核心:放弃内部特权 → 多机房正规签约 → 品牌化合规运营九、全文核心复盘与行业启示
回望整场从 Multacom 大楼租赁纠纷延伸出的十五年行业恩怨,从来不是简单的善恶对错,而是规则漏洞、内控缺失、制度差异交织出的必然结果。
2019 年的拔线事件,本质不是商家恶意跑路,而是内部员工利用机房批发计费规则、企业内控漏洞完成的商业套利;QuadraNet 依法止损但手段野蛮,无辜用户沦为最大牺牲品。整场风波没有刑事追责、没有公开诉讼,根源不在于监管缺位,而是 LLC 法人隔离、司法举证门槛、检察资源分配三重制度壁垒共同导致。
QuadraNet 的衰落并非单纯被 Dustin 掏空,而是自身粗放管理、战略误判、零售运营能力缺失的集中爆发;而 Dustin 借助行业规则完成原始积累后,果断切换合规赛道,依靠多机房分散布局、品牌化营销,成功洗白并跻身行业新锐。
对于普通 VPS 用户而言,RackNerd 如今的稳定性,从不取决于创始人的经营理念,而是依赖 ColoCrossing 等上游机房的合同连续性;Multacom 大楼的租赁纠纷、DC2 机房的反复迁移,都是底层基础设施脆弱性的真实体现。在廉价 IDC 行业里,永远不要轻信永久低价与品牌光环,历史的黑料不会消失,只会隐藏在一次次机房迁移与品牌迭代之中。
—
> *整理自一次系统性质询对话 https://yb.tencent.com/s/zXjC07ntim6k(工具检索:PACER/CourtListener/CA SOS/行业档案交叉校验),部分链路(Julian Jin 真实身份、Adam NG 去向)受限于 LLC 隐私规则不可再深入。*